hexo一直是静态博客的首选之一,它开箱即用的特点以及相对丰富的主题选择让使用者可以聚焦于博客内容的编写,同时拥有一个相对美观的界面。但如果你是一个对博客内容有高度自定义需求的开发者,且并没有分享博客主题的诉求,hexo的主题开发会是一定的挑战,因为你需要在其基础上进行主题模版开发,而不能自由选择心仪的技术栈。
本文将从静态博客的核心原理出发,以我个人的博客为例,阐述如何选择合适的技术栈,来搭建一个最基础的静态博客应用。
本文参考仓库:b-sirius.github.io
静态博客从哪里来
首先,静态博客是什么?
博客,一般至少涉及两个页面(模块):文章列表页、文章详情页。
静态,意味着不依赖服务端,意味着用户访问的内容,就是一堆已经板上钉钉写死的html、css、js代码。
这堆代码从哪里来?互联网的蛮荒时代,可能是人们一个个手写的,但现在显然不是,它们必然是编译产物。
为了能够设计我们自己的博客,我们不妨从hexo入手,先看看hexo的编译产物是什么——
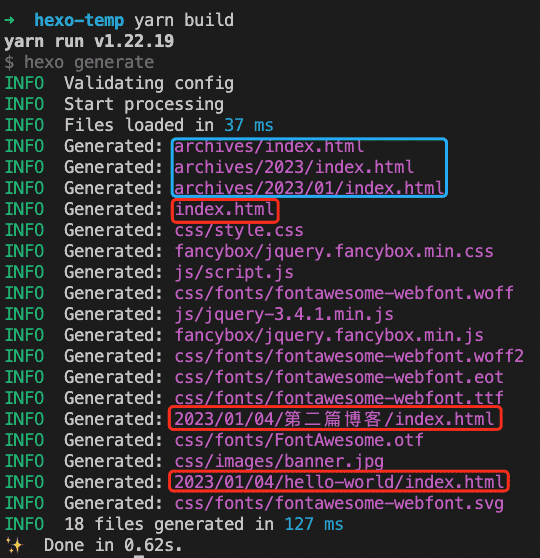
上图是典型的hexo的编译产物,我们关注一下html的入口文件:
- 蓝框部分,是博客的“归档”功能,不属于上面提到的博客基本页面,就先无视。
- 红框部分,首先是一个
index.html,这是博客列表页;其次是${date}/${title}/index.html,这是两个博客详情页,对应着两篇博文。
而在hexo项目中,你需要自定义的内容很简单,自然就是博客内容markdown文件,都存放在source/_posts目录中。

因此,hexo的基本思路就是,将文件夹内的一系列markdown文件,构建成用户最终访问的文章列表页与文章详情页。最后部署的就是这份构建产物。
以下为一个典型的使用hexo搭建静态博客的流程:
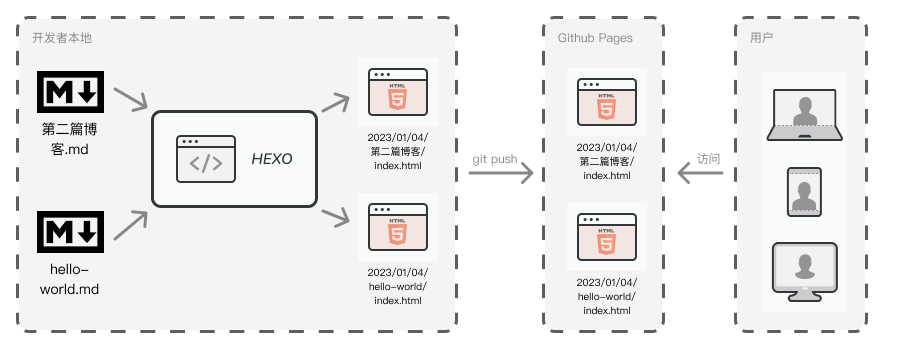
那么hexo是不可替代的么?
当然不是,从上图中可以看出,hexo是一个SSG框架,如果你不熟悉SSG,可以先去了解一下CSR,SSR和SSG是什么。
因此,只要是支持SSG的框架都可以用于静态博客的开发。我个人选择了React系的Next.js,其他框架如vue-ssg也都是可以使用的。
博客功能
现在我们知道了静态博客大体是如何工作的,也确定了使用的框架。
项目初始化完毕,面对着hello-world的一张白纸,该考虑如何实现博客的具体功能了。
文章列表
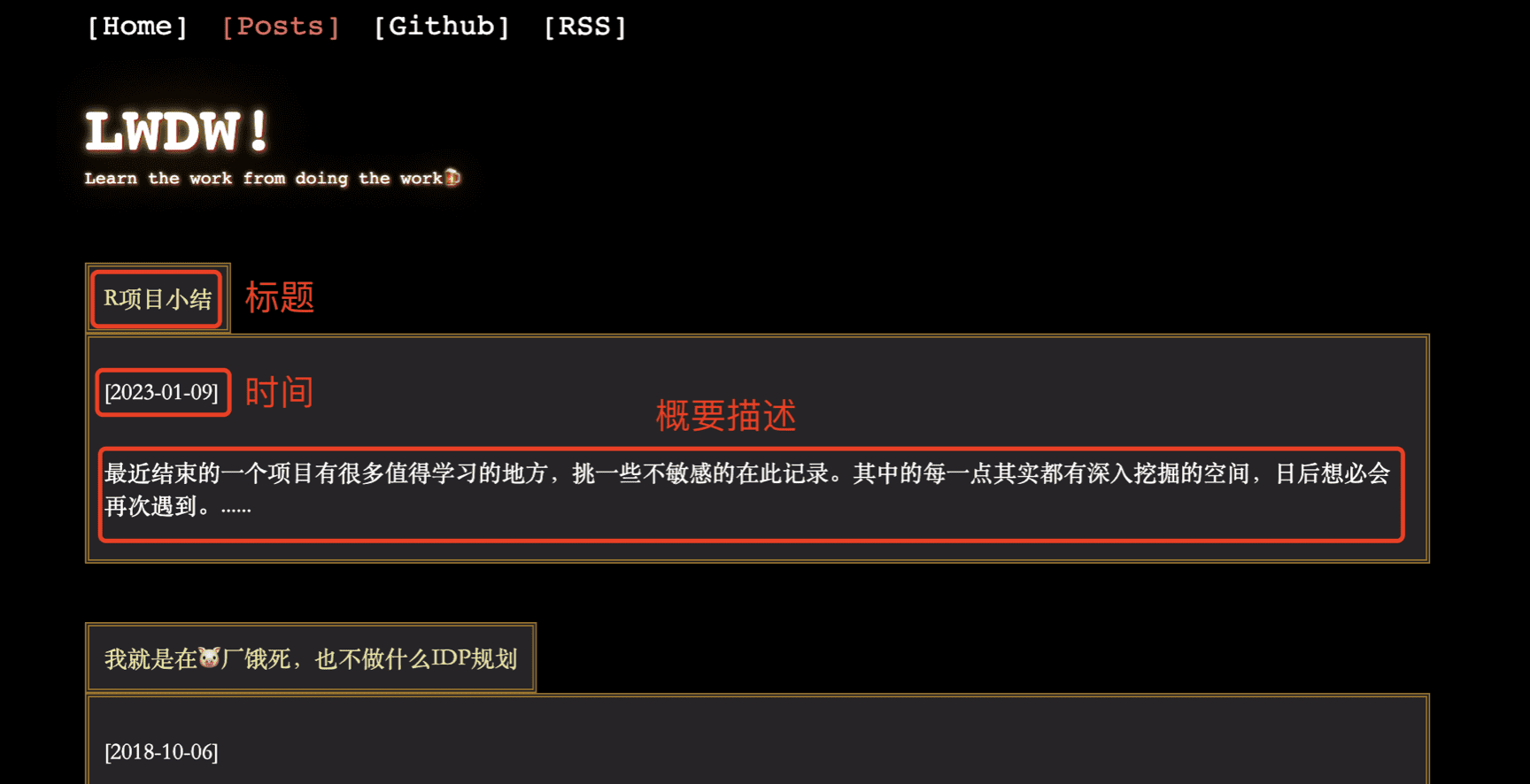
Feature list:
- 列表由一个个文章描述的卡片堆叠而成。
- 每个卡片的内容有:标题、文章发布时间、文章描述。
- 列表为按时间倒序排序。
- 点击卡片后,可以跳转到文章的详情页。
而我们的原材料只有文件夹内的一堆md文件,显然我们会遍历这个文件夹,并读取各个文件,以获得信息。
且由于SSG的特性,这个步骤会在开发者本地或服务端(即非浏览器端、客户端)完成,因此需要用到node。
读取文件信息
读取文件,自然要用到node的fs,由于fs不支持Promise,额外引入fs-extra也是不错的。
const fse = require('fs-extra');
const postFileNames = await fse.readdir('./_posts'); // postFileNames会是一个文件名列表
有了文件名列表,就可以组装出每个文件的访问路径(使用process.cwd获取当前路径)。
const path = require('path');
const mdPathList = postFileNames.map((name) => ({
name,
path: path.join(process.cwd(), '_posts', name)
}))
于是我们就可以遍历访问到每个文件的具体信息。
const matter = require('gray-matter');
for (const { name, path } of mdPathList) {
const mdData = await fse.readFile(path);
const { data: mdInfo, content } = matter(mdData);
const { title, date, skip = false } = mdInfo;
// ...
}
这里涉及到一个非常实用的工具gray-matter,它可以读取出文件的front-matter,即yaml格式的一段文本。
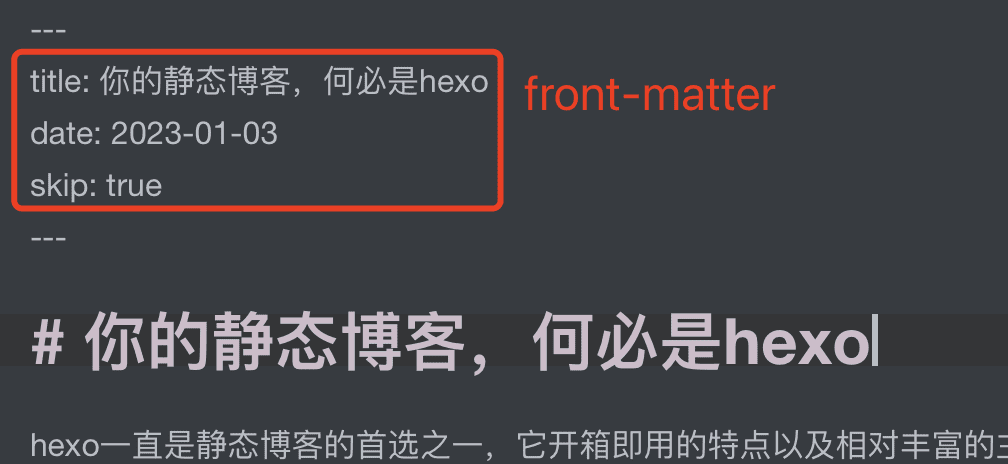
于是我们获得了每篇博客的标题与日期。
获取博客的概要描述
当然,概要描述也是可以写在front-matter中,尤其是概要与正文内容相互独立的时候。
但如果是像我这样的懒人,只想用正文中的一段话当概要,自然这个时候要从正文内容中去读取并截取文本了。
由于我们读取到的文件是markdown的原始内容,会有## ---这样的标记符号,且我们也不希望描述是一个二级标题,而是正文文本,所以就需要用到一些正则匹配,来获取到一段纯文本描述。
以下方法来自于stackoverflow,可以用于参考。
function getDescription(md) {
// 标题、列表、表格这些都是我们不想用于描述的,需要通过正则过滤掉
const regex = {
title: /^#\s+.+/,
heading: /^#+\s+.+/,
custom: /\$\$\s*\w+/,
ol: /\d+\.\s+.*/,
ul: /\*\s+.*/,
task: /\*\s+\[.]\s+.*/,
blockQuote: />.*/,
table: /\|.*/,
image: /!\[.+\]\(.+\).*/,
url: /\[.+\]\(.+\).*/,
codeBlock: /`{3}\w+.*/,
};
const isTitle = (str) => regex.title.test(str);
const isHeading = (str) => regex.heading.test(str);
const isCustom = (str) => regex.custom.test(str);
const isOl = (str) => regex.ol.test(str);
const isUl = (str) => regex.ul.test(str);
const isTask = (str) => regex.task.test(str);
const isBlockQuote = (str) => regex.blockQuote.test(str);
const isImage = (str) => regex.image.test(str);
const isUrl = (str) => regex.url.test(str);
const isCodeBlock = (str) => regex.codeBlock.test(str);
if (!md) return "";
const tokens = md.split("\n").filter(item => !!item); // 去除了空行
for (let i = 0; i < tokens.length; i++) {
if (
isTitle(tokens[i]) ||
isHeading(tokens[i]) ||
isCustom(tokens[i]) ||
isOl(tokens[i]) ||
isUl(tokens[i]) ||
isTask(tokens[i]) ||
isBlockQuote(tokens[i]) ||
isImage(tokens[i]) ||
isUrl(tokens[i]) ||
isCodeBlock(tokens[i])
)
continue;
// 返回第一个非上述匹配的内容
return `${tokens[i].slice(0, 100)}......`;
}
return ""
}
生成博客id
对于每一篇博客,我们最终都需要一个唯一的id,一种方法是直接用标题作id(博客标题显然不应该重复)。不过我们一般需要做一些encode(encodeURIComponent),否则中文在url中很容易出问题。
只不过这种方式生成的URI一般会超级超级长,所以我个人用一些简单的方法生成了数字id,并最终存储为在一个json文件中。
最后我生成了一个json文件,用于存储这些描述信息。

预渲染的动态路由
既然我们事先就知道博客有哪些,且有了一份json文件映射好了id与文件的关系,因此动态路由自然是可以预渲染的。
下面是next.js中预渲染的方法:getStaticProps。
// postMap是上文中生成的json文件
export async function getStaticPaths() {
return {
// path即预渲染的路由
paths: Object.keys(postMap).map(id => ({
params: { id }
})),
fallback: false
}
}
export async function getStaticProps(context) {
// 此处的id就是上面的id
const { id } = context.params;
const { name, title, date } = postMap[id];
const mdData = await fse.readFile(`${postsDirPath}/${name}`);
const { content: mdText } = matter(mdData);
return {
props: {
id,
title,
date,
mdText,
}
}
}
文章详情
文章详情中的关键点是,如何将markdown渲染为用户友好的Html,你可能会需要做以下几件事:
Markdown to Html
这里可以用React-Markdown来实现,显然它React友好。具体的用法就不赘述了。
不过需要注意的是,React-Markdown需要在客户端运行,因此我们不能直接将其写在render中,而是要异步渲染(可以使用useEffect)。
高亮code
同样我们有一个可以配套使用的package:react-syntax-highlighter。
配合ReactMarkdown的components属性,可以对code进行定制。
支持锚点
如果我们想要使用目录导航,标题的锚点就非常重要了。
同样在ReactMarkdown的components属性,可以对h2,h3等进行定制,在这里添加生成锚点的逻辑。
支持html in markdown
如果你要在markdown中插入codepen、sandbox之类的代码示例,一般都需要采用html in markdown的方式,默认情况下ReactMarkdown会将所有html标签都无害化处理,想要让这些html生效,可以使用rehype-raw。
完整代码
请见github。
RSS支持
RSS的本质其实很简单,它是一份按照规则定制的静态xml文件,内容是需要阅读的内容的基础信息。我们之前已经处理过文章列表,其中包含的信息恰恰就是博客的RSS应该包含的:标题、日期、简介、跳转地址。而RSS订阅源会通过这个xml的文件地址来进行拉取。
当然,有RSS这个包可以帮助我们生成这个xml文件,并不复杂,可以直接参考代码。
博客体验
在上面提到的CSR,SSR和SSG是什么,其中提到了SSG的性能是很好的。但真正影响博客体验的要素是很多的,我觉得可以从以下几方面来考虑:
- 理论性能、体验,可以用Chrome的Lighthouse来测试,适合作为参考。
- bundle是否合理,可以使用
@next/bundle-analyzer之类的库来帮助分析。 - 设备适配性:大致从移动端、平板、电脑这几种设备类型来考虑。
- 视觉是否合理;
- 交互是否合理;
- 请求资源是否合理(如请求的图片尺寸);
- 网络环境,可以用站长工具的网站测速工具,检查对大陆用户是否友好。
- 社交平台分享友好,是否有favicon.ico,是否有相应的metadata配置。
- SEO优化,同样可以用站长工具帮助检查。
以上基本就是我在搭建自己的静态博客时,所考虑到的东西。许多提到的可优化项或许还没有实施,但还是欢迎来访问我的博客LWDW!,同时也可以查看我的github仓库,作为实现的参考。